论文阅读-GhostVLAD-GhostVLAD for set-based face recognition
GhostVLAD,一句话可以囊括:在NetVLAD上的小修小补。
这两篇论文有一个共同的作者:Dr Relja Arandjelović,他还是NetVLAD的一作。
说到这里,大家心里应该有点谱了吧,这篇GhostVLAD的创新点,只有两点:
- 在NetVLAD的基础上,加了一个类别簇(ghost clusters);
- 为创新点 1 构造了一个应用场景:基于模板的人脸识别(template-based face recognition)。
且看下文如何分解。
1. Set-based face recognition
所以啥叫基于模板的人脸识别?其实就是构造的这样一个场景:
你有一个数据库,存储了很多人的人脸图片,其中每个人都有多张图片,现在你采集到了一个人的一些图片,如何 利用采集到的图片来进行认证(verification)和识别(identification)?
好了,理解了上面这个绕口的场景之后,作者开始为此构造约束条件了:
你需要训练一个网络,这个网络要满足:
a. 输入可以是任意数量图片,同时为了能够进行比对,输出应该是一个固定长度的描述子;
b. 输出的描述子应该足够简洁,这样才能在进行比对的时候节约内存和运算时间;
c. 输出的描述子要足够有辨别性,从而使得类内相似性远远大于类间相似性。
看完了这几个约束条件,聪明的你一定在心里犯嘀咕了:这不是废话么~
嘘,尊重作者,君且安坐,看我写来。
2. 网络架构
要我说,网络结构跟NetVLAD没啥区别,但这样有点欺负人了:所有的CNN网络架构还都没啥区别呢。
所以,还是有点点区别的,看图:
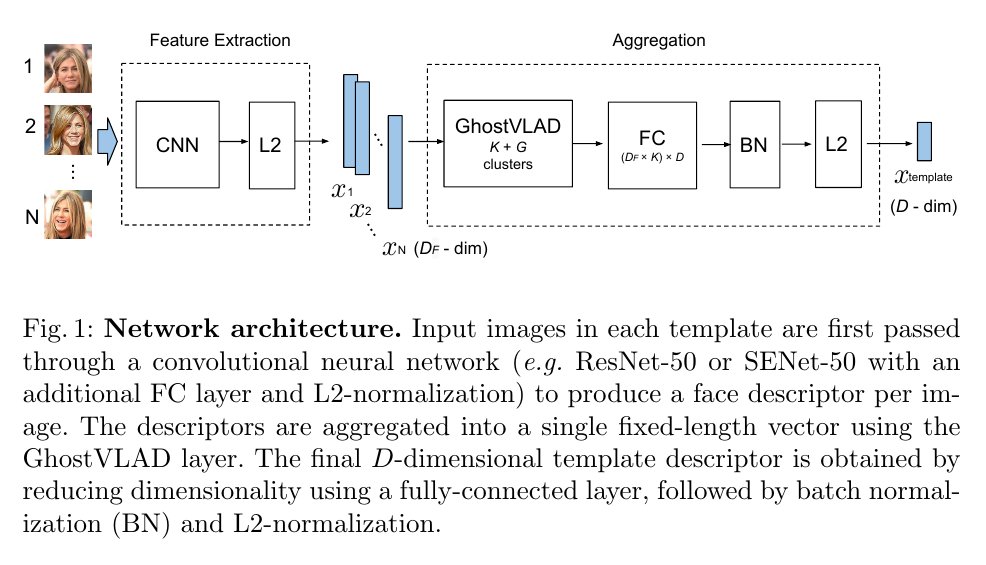
以示公平,我把NetVLAD的网络架构图也放出来:
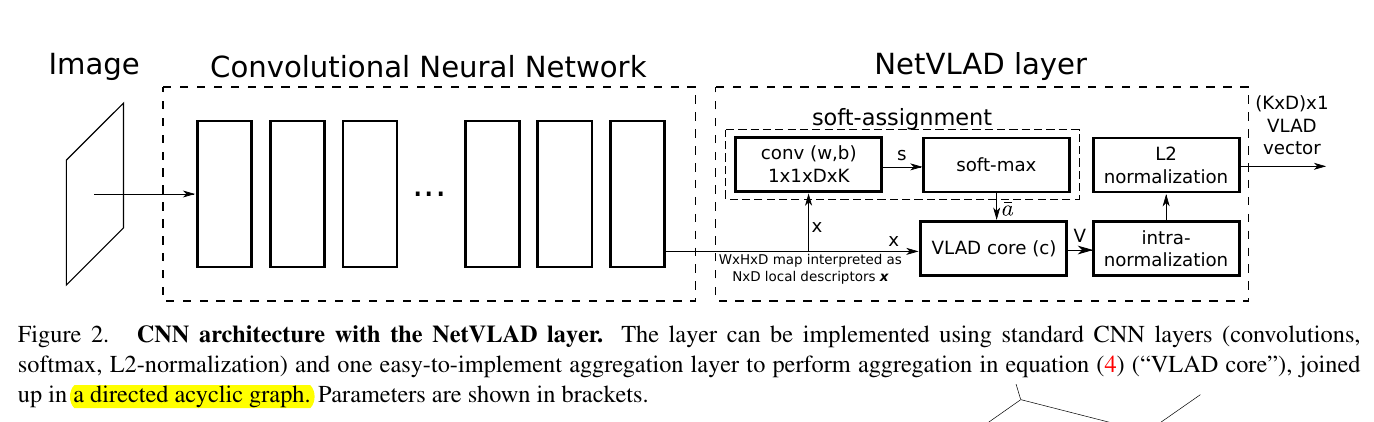
怎么样,两个网络架构还是有那么点区别的吧?
言归正传,ghostVLAD的架构,很清晰:
- Feature extraction: 用个预训练的 backbone 提取特征;
- Aggregation: 把提取到的多个图片的多个特征聚合为一个描述子。
backbone论文里用的是 ResNet-50 和 SENet-50,当然,要去掉最后的池化层。
同时,作者为了达到上面提到的要求 b ,又在 backbone 的后面加了个全连接层,使得输出维度从 2048 降为128/256。
是不是有点意外?一开始看人家介绍要求 b 的时候,是不是以为要放什么大招呢?
然后特征的聚合就用到了所提出的 GhostVLAD 了。这个下一节展开来讲。
3. GhostVLAD: NetVLAD with ghost clusters
这一节的节标题就是作者原文里的标题。哈哈,看到这个标题,觉不觉得作者好像还算挺实诚的?
GhostVLAD的作用,就是给定 N 个 $D_F$ 维的人脸图像描述子,将其转换为一个 $D_F*K$ 的输出。
然后这个输出再经过一层全连接层,得到一个 D 维的向量。
关于NetVLAD的详细介绍,请看我的另一篇博文: 论文阅读 NetVLAD: CNN architecture for weakly supervised place recognition.
这里就不赘述了。
而 GhostVLAD 又是怎么回事呢?看图:
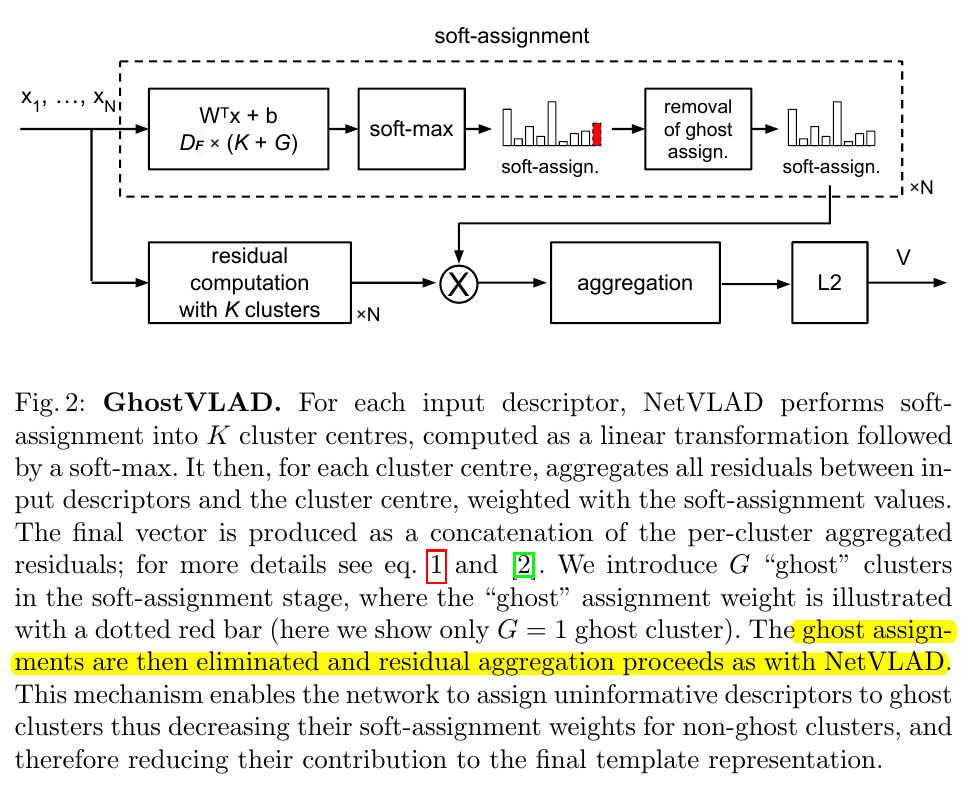
诸君请看,图中的那个红色区域的柱状框,就是该论文的创新点!就是论文所说的“Ghost”!
什么意思呢?就是在计算 VLAD 的时候,多加了 “Ghost clusters”, 但是在向后传递的时候,又把
“Ghost clusters” 给去掉了,不算在内。
这样一来,整个网络训练的时候,有些图片会被聚类到“Ghost clusters”,但又不会参与到整个网络的权重更新中。
它在那里,又好像不在那里,所以称为“Ghost clusters”。
通过端到端的训练,来让网络自主选择哪些图片作用较低,应该成为“Ghost clusters”。
当然,对于这个特定的 set-based face recognition 场景,我们当然是期望那些模糊的、信息量较低的图像成为“Ghost clusters”。
不得不说,这个想法我还是挺佩服的,敬仰。
下文就是大家司空见惯的一些日常流程了:训练数据、数据增强、训练过程、参数初始化等等,乏善可陈,就不赘述啦~~
4. Analysis of ghost clusters
这里作者论证了一下这个 ghost clusters 的有效性:
因为 GhostVLAD 聚合的是一系列图像的描述子的残差向量,而残差向量是每个 non-ghost cluster的加权
残差值,所以可以通过计算这些残差向量的模来衡量其对于这一系列图片的贡献程度。
绕不绕?没关系,我帮你总结一下:因为某些原因,可以推论认为向量的模越大,其贡献程度越大。
所以那些清晰的、信息量多的图像的模应该较大,对应的,模糊的、信息量少的图像的模应该较小。
那么事实如何呢?作者画了个图:

恩,还好,可以自洽。
然后放张结果对比图:
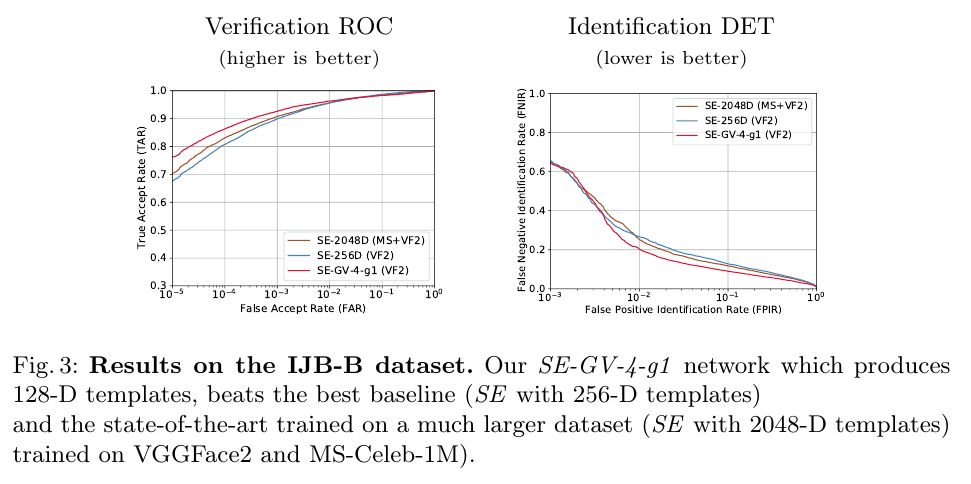
完结撒花。
5. Conclusions
看到了这里,相信客官应该觉得我开头所言非虚了吧:
不过当然,“小修小补”没什么意外,但知道怎么样进行”小修小补“就非常厉害啦。
人家的想法确实很令我佩服,敬仰。在这里送上我的膝盖:

以上,完结撒花。
regards.